线性和逻辑回归中的正则化
正则化指的是降低模型的复杂度以减少过拟合。泛化是指模型很好地拟合以前未见过的新数据(从用于创建该模型的同一分布中抽取)的能力。
过拟合
过拟合模型在训练过程中产生的损失很低,但在预测新数据方面的表现却非常糟糕。如果某个模型在拟合当前样本方面表现良好,那么我们如何相信该模型会对新数据做出良好的预测呢?正如您稍后将看到的,过拟合是由于模型的复杂程度超出所需程度而造成的。机器学习的基本冲突是适当拟合我们的数据,但也要尽可能简单地拟合数据。
一个回归问题的例子:
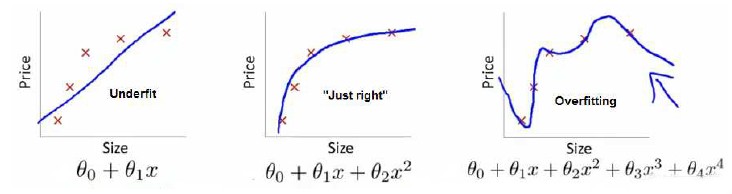
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
出现了过拟合问题,应该如何处理?
- 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
- 正则化。 保留所有的特征,但是减少参数的大小(magnitude)
正则化线性回归 -- L₂ 正则化
我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。
也就是说,并非只是以最小化损失(经验风险最小化)为目标:$minimize(Loss(Data|Model))$
而是以最小化损失和复杂度为目标,这称为结构风险最小化:
$minimize(Loss(Data|Model) + complexity(Model))$
现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。
我们使用 L2 正则化公式来量化复杂度,该公式将正则化项定义为所有特征权重的平方和:
$L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 + ... + w_n^2}$
在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。
正则化线性回归的代价函数为:
$J\left( \theta \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{[({{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})}^{2}}+\lambda \sum\limits_{j=1}^{n}{\theta _{j}^{2}})]}$
如果我们要使用梯度下降法令这个代价函数最小化,因为我们未对 $\theta_0$ 进行正则化,所以梯度下降算法将分两种情形:
Repeat until convergence{
${\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}})$
${\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}]$ $for$ $j=1,2,...n$
}
对上面的算法中 $ j=1,2,...,n$ 时的更新式子进行调整可得:
${\theta_j}:={\theta_j}(1-a\frac{\lambda }{m})-a\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}$
可以看出,正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令值减少了一个额外的值。
正则化率
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为 lambda(又称为正则化率)的标量。也就是说,模型开发者会执行以下运算:
$minimize(Loss(Data|Model)+λ complexity(Model))$
执行 L2 正则化对模型具有以下影响
- 使权重值接近于 0(但并非正好为 0)
- 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
增加 lambda 值将增强正则化效果。
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
- 如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。
- 如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
注意:将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
正则化逻辑回归模型
正则化在逻辑回归建模中极其重要。如果没有正则化,逻辑回归的渐近性会不断促使损失在高维度空间内达到 0。因此,大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:
- L2 正则化。
- 早停法,即,限制训练步数或学习速率。
给逻辑回归代价函数增加一个正则化的表达式,得到
$J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {h_\theta}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{h_\theta}\left( {{x}^{(i)}} \right) \right)]}+\frac{\lambda }{2m}\sum\limits_{j=1}^{n}{\theta _{j}^{2}}$
其中:${h_\theta}\left( x \right)=g\left( {\theta^T}X \right)$




相关推荐
深度学习 -- 损失函数
深度残差网络(Deep Residual Networks (ResNets))
深度学习 -- 激活函数
神经网络训练 -- 调整学习速率
生成对抗网络(GAN)改进与发展
生成对抗网络(GAN)优点与缺点
生成对抗网络(GAN)的训练
生成对抗网络(GAN)基本原理
生成模型与判别模型