降低损失 -- 梯度下降法
梯度下降算法
梯度下降是一个用来求函数最小值的算法。
梯度下降法算法会计算损失曲线在起点处的梯度。梯度是偏导数的矢量;它可以让您了解哪个方向距离目标“更近”或“更远”。请注意,损失相对于单个权重的梯度就等于导数。
梯度是一个矢量,因此具有以下两个特征:方向和大小。梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法算法会沿着负梯度的方向走一步,以便尽快降低损失。
这里我们使用梯度下降算法来求出代价函数 $J(\theta_{0}, \theta_{1})$ 的最小值。
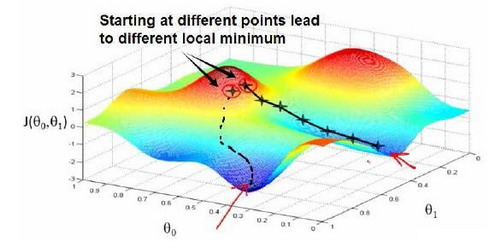
梯度下降背后的思想是:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
批量梯度下降(batch gradient descent)算法的公式为:
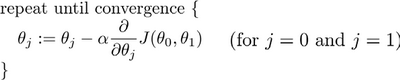
其中 $a$ 是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。

在梯度下降算法中,我们要更新 ${\theta_{0}}$ 和 ${\theta_{1}}$,当 $j=0$ 和 $j=1$ 时,会产生更新,所以你将更新 $J\left( {\theta_{0}} \right)$ 和 $J\left( {\theta_{1}} \right)$。实现梯度下降算法在这个表达式中,如果你要更新这个等式,需要同时更新 ${\theta_{0}}$ 和 ${\theta_{1}}$,我们要这样更新:
${\theta_{0}}$ := ${\theta_{0}}$ ,并更新 ${\theta_{1}}$ := ${\theta_{1}}$。
实现方法是:你应该计算公式右边的部分,通过那一部分计算出 ${\theta_{0}}$ 和 ${\theta_{1}}$ 的值,然后同时更新 ${\theta_{0}}$ 和 ${\theta_{1}}$。
也就是这个过程:

在梯度下降算法中,这是正确实现同时更新的方法。同时更新是梯度下降中的一种常用方法,是更自然的实现方法。
随机梯度下降
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数。到目前为止,我们一直假定批量是指整个数据集。就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本。此外,Google 数据集通常包含海量特征。因此,一个批量可能相当巨大。如果是超大批量,则单次迭代就可能要花费很长时间进行计算。
包含随机抽样样本的大型数据集可能包含冗余数据。实际上,批量大小越大,出现冗余的可能性就越高。一些冗余可能有助于消除杂乱的梯度,但超大批量所具备的预测价值往往并不比大型批量高。
如果我们可以通过更少的计算量得出正确的平均梯度,会怎么样?通过从我们的数据集中随机选择样本,我们可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。
随机梯度下降法 (SGD) 将这种想法运用到极致,它每次迭代只使用一个样本(批量大小为 1)。如果进行足够的迭代,SGD 也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。
小批量随机梯度下降法(小批量 SGD)是介于全批量迭代与 SGD 之间的折衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
梯度下降法也适用于包含多个特征的特征集。




相关推荐
深度学习 -- 损失函数
深度残差网络(Deep Residual Networks (ResNets))
深度学习 -- 激活函数
神经网络训练 -- 调整学习速率
生成对抗网络(GAN)改进与发展
生成对抗网络(GAN)优点与缺点
生成对抗网络(GAN)的训练
生成对抗网络(GAN)基本原理
生成模型与判别模型