模型训练与损失 -- 代价函数
模型训练与损失
训练模型表示通过有标签样本来学习(确定)所有权重和偏差的理想值。在监督式学习中,机器学习算法通过以下方式构建模型:检查多个样本并尝试找出可最大限度地减少损失的模型;这一过程称为经验风险最小化。
损失是对糟糕预测的惩罚。也就是说,损失是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为零,否则损失会较大。训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。
平方损失:一种常见的损失函数
线性回归模型使用的是一种称为平方损失(又称为 L2 损失)的损失函数。单个样本的平方损失如下: (y - y')2
均方误差 (MSE) 指的是每个样本的平均平方损失。要计算 MSE,请求出各个样本的所有平方损失之和,然后除以样本数量:
$MSE = \frac{1}{N} \sum_{(x,y)\in D} (y - prediction(x))^2 $
其中:
(x,y) 指的是样本,其中
- x 指的是模型进行预测时使用的特征集。
- y 指的是样本的标签。
prediction(x) 指的是权重和偏差与特征集 x 结合的函数。
D 指的是包含多个有标签样本(即 (x,y))的数据集。
N 指的是 D 中的样本数量。
现在要做的是为我们的模型选择合适的参数(parameters)$\theta_{0}$ 和 $\theta_{1}$,也是直线的斜率和 轴上的截距。
我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
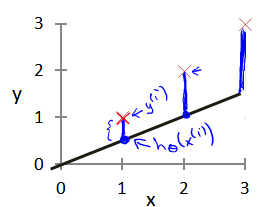
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数
$J \left( \theta_0, \theta_1 \right) = \frac{1}{2m}\sum\limits_{i=1}^m \left( h_{\theta}(x^{(i)})-y^{(i)} \right)^{2}$最小。
我们绘制一个等高线图,三个坐标分别为 $\theta_{0}$ 和 $\theta_{1}$ 和 $J(\theta_{0}, \theta_{1})$:
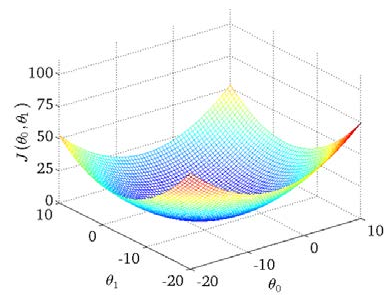
看出在三维空间中存在一个使得 $J(\theta_{0}, \theta_{1})$ 最小的点。




相关推荐
深度学习 -- 损失函数
深度残差网络(Deep Residual Networks (ResNets))
深度学习 -- 激活函数
神经网络训练 -- 调整学习速率
生成对抗网络(GAN)改进与发展
生成对抗网络(GAN)优点与缺点
生成对抗网络(GAN)的训练
生成对抗网络(GAN)基本原理
生成模型与判别模型